Quantitative and Qualitative Analysis of Time-Series Classification Using Deep Learning

Introduction
A time-series is a series of observations expressed as temporal data points ordered in time, such as stocks market, human activity, audio, etc. Classification is a predictive modeling problem included in time-series data mining tasks [1]. Different classification problems are caused once dealing with rich and diverse-range time-series data domains such as, finance, medical science and engineering [2]. Variant experiments are conducted by UCR repository, the biggest set of real-world time-series data [3]. These actions along with many others are untaken in order to solve time-series classification problems [4]. Time-series classification techniques can be basically categorized to three main divisions of distance-based, using a distance function for similarity measurement, model-based, using statistical models for classification, and feature-based, using feature vectors classification methods [5].
Euclidean Distance (ED) and Dynamic Time Warping (DTW) are commonly used measurements in distance-based methods. The classification task is done by metric classifiers, such as Support Vector Machines (SVM) and K-Nearest Neighbors (KNN). SVM classifiers have been using embedded distance features for time-series data by computing EDs inside the classification task [6]. The SVM method is an effective approach in case of high dimensional data and superior in classification accuracy [7]. KNN classification is done by using the most frequent label in the k closest data points. The 1-Nearest Neighbor classifier with DTW distance (1NN-DTW) is the most effective time-series classifier, however it carries high computational cost as a concern [8]. 1NN-DTW classifier has shown a simple but strong golden baseline by achieving comparable results among other classifiers [9], [10]. Therefore, latest developments have focused on overpowering the 1NN-DTW method in time-series classification tasks [11].
Simple time-series representations, such as naïve Bayes and Hidden Markov Model (HMM), are classified using model-based methods. A naïve Bayes classifier selects the highest conditional probability among every class features [5]. HMM has also been used to classify time-series data into time-step related states probabilistically [12]. Feature-based methods, such as decision trees, Shapelet Transform (ST), and Artificial Neural Networks (ANNs), perform a feature extraction procedure to classify vector of features instead. Time-series shapelets are similar subsequences presented as features for classification [13]. Using decision tree classifiers based on time-series shapelets has led to faster and more accurate results [14]. Shapelet-based algorithms have also provided interpretable results with low performance on early time-series classification [15]. Researchers are considering ANNs for time-series manipulation mostly in modeling and forecasting [16]. Moreover, ANNs have received inconclusive results in case of complex nonlinear data classification tasks using their nonlinear learning ability [17].
Non-automatic feature selection is a challenging stage for numeric data which may lead to information loss through discretization [18]. Variant Machine Learning (ML) state-of-the-art classifiers were evaluated on both univariate and multivariate time-series datasets because of their great performance. ML algorithms are modified to more accurate time-series classifiers, as their limited performance is probably due to the high dimensionality of large time-series datasets [19]. In recent years, deep learning has become extremely popular and widely applied to a number of classification tasks. Deep learning frameworks automatically learn and extract features from raw data, not requiring individual hand-crafted features [20]. These methods are applied to univariate as well as multivariate time-series datasets by supporting multiple inputs and outputs [21].
Deep learning methods for time-series classification can be characterized in terms of generative and discriminative models. Generative approach contains Autoencoders and Echo State Networks (ESNs), while discriminative approach contains feature engineering and end-to-end methods [11]. ESNs are used for modeling and classification of nonlinear time-series [22]. These algorithms have been applied to different time-series data, studying the effects of ESNs network architecture on data characteristics [4]. Autoencoders are used to pre-train time-series classifiers as nonlinear feature extractors. Autoencoder deep neural networks such as Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) have been at the center of recent studies. These methods are outperforming traditional methods for time-series classification in terms of automatic deep feature generation, classification accuracy and noise tolerance [23]. Recently, a Long Short Term Memory (LSTM) RNN model has been proposed for more accurate and less complex image time-series classification, and also another trained deep RNN approach has provided useful representations for time-series classifiers [24], [25].
Nowadays, different machine learning and deep learning methods are considering time-series data collected from all sorts of domains including industry, medicine, finance, and agriculture, for variant applications such as image, video, gesture, motion, signal, agricultural, and fault classification. Due to the variety of applications, a significant number of publications are conducted in time-series classification field, noting that recent studies are mostly focused on using deep learning based algorithms for the tasks. Readers can find several comprehensive reviews and surveys in time-series data mining tasks and, more specifically, in using deep learning methods for time-series classification. The review papers have provided technical information about basic definitions, theories, and structures; existing literatures, their methods and outcomes; and current and future methods, applications and challenges [1], [5], [11], [19]. In contrast to the reviews mentioned above, a Bibliometric analysis has been carried out in this paper to visualize the trends in existing literature and overview current state-of-the-art topics to help future research.
Unlike traditional narrative literature reviews, which rely on the experience and knowledge of the researchers, bibliometric analysis provides a perspective that can easily be scaled from micro to macro levels [26], [27]. Bibliometrics is defined as measuring academic and organizational performance based on several indicators such as number of publications, number of citations, and collaboration networks [28]. Bibliometric analysis is a powerful tool for quantitatively investigating scientific outputs [29]. Bibliometric analysis of scholarly publications, lead to development of different metrics gaining insight into the intellectual structure of a broad academic discipline and evaluating the impact of scientific documents [30], [31]. A bibliometric study analyses the research productivity, top-cited publications, countries’ scholarly outputs, most frequent keywords and the trend of publications to quantitatively explore a specific research area [32].
There are many Bibliometric analyses applied in different fields of studies including research performance in social science [33], green supply chain [34], knowledge management [31], university research performance [35], fuzzy research [36], drug delivery [32] and many others. Meanwhile, there are also a few Bibliometric studies close to the research area of time-series classification using deep learning, such as global research on artificial intelligence [37], analysis of global remote sensing research [38], support vector machines research trend [39], temporal topic modelling [40], analysis of affective computing researchers [41], and application of artificial intelligence to wastewater treatment [42]. However, none of these studies directly concentrates on using deep learning for time-series classification tasks. On one side, the previous published studies have not treated bibliometric approach in the field of time-series classification using deep learning to the best of our current knowledge. On the other side, bibliometric analysis alone cannot be a substitute for qualitative peer assessment [43]. Therefore, bibliometric results should be used with precautions to evaluate the relevant scholarly outputs [44]. Using qualitative analysis alongside a bibliometric study will elaborate more insight into scholarly outputs [45], [46]. Therefore, top papers for qualitative analysis were selected based on annual citation rate. Citation analysis is an important method of evaluating the impact of a research article [47]. The number of publication citations reflects its contribution to the field of interest and it is often considered as a proxy for its influential [48]. This research aims to explore the research status of deep learning frameworks used for time-series classification tasks, within the past decade, by both the bibliometric and the qualitative approaches. The study highlights the research focuses and hotspots of time-series classification algorithms and applications, that enable scholars to understand the develop trajectories, the key factors of current research, and future challenges of the research area.
Methodology
There are two major databases for collecting the scholarly publications data, namely Web of Science (WoS)1 and Scopus2 [49].
While WoS is considered one of the largest and most trustworthy
databases for literature retrieval and analysis, the journal coverage of
Scopus appears more comprehensive than WoS [50]. To choose a suitable database for the current research, a primary title search of “classification” [5]
and a topic search of (“time series” OR “time sequence”) were run on
both WoS and Scopus databases. The number of documents retrieved were
2,431 publications for WoS and 2,974 publications for Scopus database.
These are the number of documents published in all years, containing the
word “classification” in their title and the phrase “time series” or
“time sequence” in their title, abstract or keywords. Hence, the data
was collected from Scopus database on
In
order to select the most recent documents, results were limited to the
publications since the year 2010. Therefore, the number of retrieved
documents have dropped from 2,974 publications to 2,309. Documents of
the year 2020 are excluded from the results, and the final data consists
of a total number of 2,201 documents. These are the documents published
during 2010–2019 about all variant frameworks and applications for
time-series classification task. The VOS Viewer software [51]
is used to demonstrate annual number of publications and visualize the
top 20 productive countries and the top 50 keywords in time-series
classification research. VOS Viewer is a software which plots
distance-based maps and clusters keywords retrieved from both titles and
abstracts of research documents [52], [53].
The bibliometric visualization map includes linked nodes, where every
node is a representation of a keyword, a country, an institute, or an
author [54]. The total number of 2,201 documents were refined to 419 by (deep) AND (“neural network
There may be some limitations in data collection procedure of this study, as similarly in other bibliometric studies. The main dataset consists of publications available in Scopus database including classification in their title and either time-series or time-sequence in their topic (title, abstract or keywords). Followed by that, the final dataset is refined by publications including phrases such as either deep learning or deep neural network. However, some authors may have been using the possible synonyms of these phrases instead. Although about 95% of documents are indexed by both WoS and Scopus databases [49], the study will not cover literatures specifically from WoS database. Overall, the large number of publications considered in this bibliometric analysis ensures that the literature represents the major research efforts in time-series classification using deep learning field.
The data is analysed by Bibliometrix-package,3 which is an R-Tool for comprehensive science mapping analysis [55]. The Bibliometrix-package is designed for quantitative research in Scientometrics and Bibliometrics. The tool provides various routines for importing bibliographic data from well-known databases such as Scopus and WoS. The data collection procedure is illustrated in FIGURE 1, as Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) flow diagram [56]. The bibliometric analysis results are combined with a qualitative analysis of publications content. The top 50 most frequently cited articles, among all 419 publications, are categorized into three main subjects. Followed by that, articles with a considerable number of citation per year were selected for a qualitative literature review.

The PRISMA flow diagram for the bibliometric analysis on time-series classification using deep learning.
Quantitative Analysis
A total number of 2,201 papers were published on the topic of Time-Series Classification from 2010 to 2019. FIGURE 2 shows an exponential uptrend in the annual number of publications in Time-Series Classification research area. In early 2010, the yearly output of research papers was just above 100. However, the Time-Series Classification research productivity increased slowly over the first 3 years specifically in 2011, where 134 published documents were recorded. There was a very slight rise in publication rates in 2013 and 2015 with 152 and 193 papers respectively. As FIGURE 2 depicts, more and more scholars paid attention to this area from 2015 onwards, where the productivity has started to grow faster. This trend has continued to rise right through 2019, publishing about 459 documents in that year. In general, the yearly scientific production in Time-Series Classification is 4.06 fold during 2010–2019 period.
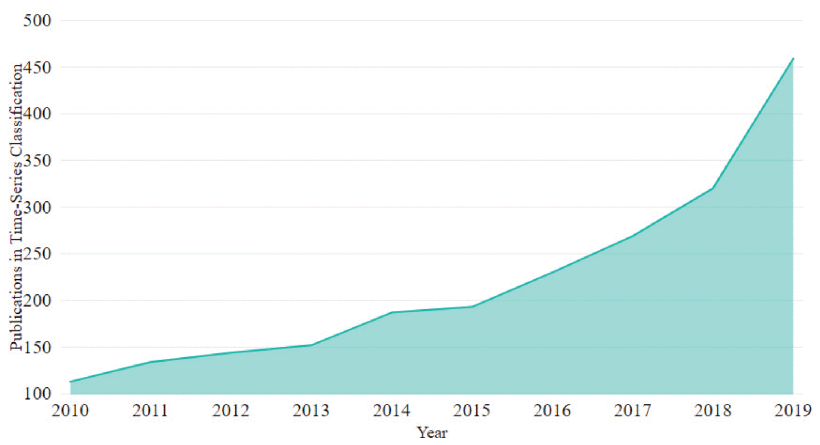
FIGURE 3 visualizes the top 20 productive countries involved in Time-Series Classification research area. The documents published by these 20 top countries was reported as 79.3% of the total number of the publications. The top list includes 11 Western countries and nine Asian countries. China is ranked first collaborating with the total number of 462 papers published, followed by the United States collaborating with 425 and Germany with 174 publications. These three countries are located in different continents: (1) China signifies the best ranking country in Asia; (2) the United States performs North and South America; and (3) Germany marks the highest publication among other countries in Europe. These information show that each continent has a leading country in Time-Series Classification research activities. It’s worth noting that China and the United States are two main research centres of this field, while Germany is in fact joining Time-Series Classification research powers in near future.

Density visualization map of top 20 countries collaboration in time-series classification bibliometric analysis.
Co-occurrence analysis has been carried out among all sorts of keywords including author’s keywords and Scopus keywords index. Keywords with the minimum number of 60 occurrences were included in the analysis. The bibliometric analysis in Time-Series Classification includes 12,107 keywords, in which an overall number of 50 met the threshold. FIGURE 4 shows the network structure of 50 high frequency author’s keywords and keywords index. Keywords different colours indicate the initial date of their related publications, and lines show the co-occurrence links between different keywords. Time-Series Classification-related publications have been using classical Algorithms and Radiometers from the very beginning in 2014. Time-Series Classification tasks started using Learning Algorithms, followed by Machine Learning approaches in 2017.
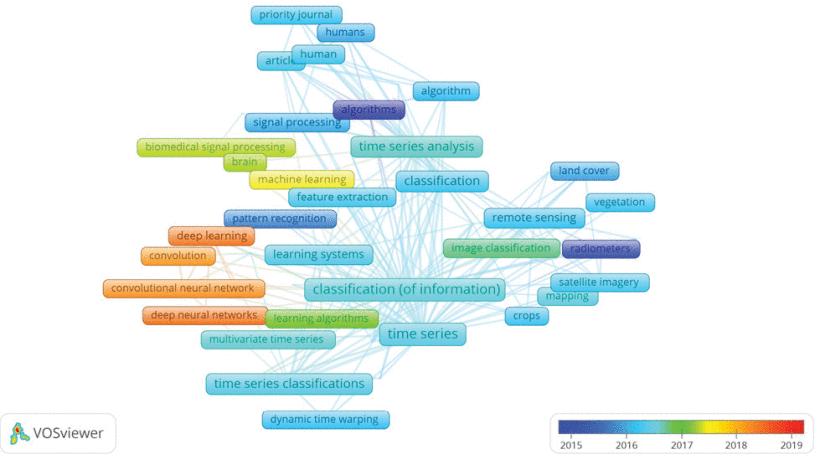
The network structure of top 50 keywords (author’s keywords and keywords index) in time-series classification bibliometric analysis.
After conducting co-occurrence analysis among keywords, it was revealed that the hottest topics in the literature are Deep Learning, Deep Neural Networks, Convolution and Convolutional Neural Network coloured in dark orange. In order to confirm the recently added keywords which may not have enough occurrences to be considered in FIGURE 4, another keywords analysis on publications of years 2018 and 2019 has been conducted. Convolutional Neural Network, LSTM, and Deep Learning are mentioned as the top three keywords during this period. Therefore, the paper focuses on Deep Learning based methods used for Time-Series Classification.
Refining the original 2,201 documents to Deep Learning methods resulted a total number of 419 documents retrieved from Scopus database. Table 1 shows the details of this result. There are 1,409 active authors using Deep Learning in Time-Series Classification tasks. The average number of authors per document is calculated as 3.36, proposing that related articles are mostly the result of collaborative research attempts. There are only 15 single-authored documents on Time-Series Classification using Deep Learning in the analysed dataset. The other 404 documents are co-authored by 1,394 different people. Considerably, the average number of authors authorizing the publications, represented as the global collaboration index, is calculated as 3.45. This shows a high trend of co-authorship in Time-Series Classification research products focused on Deep Learning algorithms. According to Table 1, the recorded average number of 6.921 citations per documents appeared to be low, demonstrating smaller number of highly cited and more low-cited publications.

FIGURE 5 indicates the rapid increase in the number of publications in Time-Series Classification using Deep Learning. As the cumulative graph shows, the area of Time-Series Classification using Deep Learning is approaching 215 publications per year in 2019. This is approximately half of the total number of 459 publications on Time-Series Classification in that year. Interestingly, the rise in the number of research productions in Time-Series Classification has slowed down compared to the fast rate of research on Time-Series Classification using Deep Learning. As it is shown in FIGURE 5, Deep Learning methods have made their place through Time-Series Classification tasks right after 2013, where the number of published documents has grown from 1 in 2013 to 12 in 2015. Continuously, a sharp growth pattern has appeared after 2015 for the research productions on Time-Series Classification using Deep Learning, which means more researchers are focusing in this new area.

A cumulative graph of publication years in time-series classification research field limited to deep learning methods from 2010 to 2019.
FIGURE 6 shows the scientific collaboration network of the top 20 countries in the analysis of Time-Series Classification using Deep Learning. The research collaboration between different countries is shown by coloured lines and their size shows the strength of cooperation between two connected countries. China, as the most productive country in Time-Series Classification research field, has remained at the first place of the list with the total of 114 published documents in Time-Series Classification using Deep Learning. These publications are mostly collaborated with the USA, followed by Canada, Singapore, Hong Kong and Finland. The USA has ranked the second by collaborating with 87 papers, just above 20% of the total publications in Time-Series Classification using Deep Learning research area since the year 2010.

The network structure of top 20 countries collaboration in time-series classification using deep learning bibliometric analysis.
As the collaboration pathways show, United Kingdom and Germany have a considerable number of joint papers. The total number of related collaborated publications is reported as 34 documents for United Kingdom and 29 documents for Germany in the time span of 2010-2019. Other high collaborative countries include France, Canada, India, Switzerland, Finland, Australia and Denmark. Different colours in FIGURE 6 show different clusters of international research cooperation. Two main country clusters can be concluded from the graph: (1) the “China, USA and Canada” community; (2) the “Germany, United Kingdom, Netherland and India” community. Other two smaller communities as “Spain, Brazil and France”, and “Australia, Switzerland and France” can be seen. These collaboration communities help researchers around the world to spot their colleagues to establish more research productions.
FIGURE 7 indicates the number of multiple and single publications in Time-Series Classification using Deep Learning across top-cited countries. The top countries are selected based on the nationality of the corresponding author. There are a total of 57 articles written by Chinese corresponding authors including nine multiple country publications (MCPs) and 48 single country publications (SCPs). American corresponding authors have made USA the most collaborative country, contributing by more than 20% of its total literature production in about 10 years. French and German corresponding authors show an equal research productivity of 17 articles in the field of Time-Series Classification using Deep Learning, in which their publications contain four and nine MCPs respectively. As FIGURE 7 shows, most published documents are written by authors from the same country, which means that authors usually collaborate with people in the same national background.

Total number of publications (multiple country publication and single country publication) by top 20 corresponding author’s countries in time-series classification using deep learning.
The 10-year development of sources in the field of Time-Series Classification using Deep Learning is shown in FIGURE 8. The graph shows the different number of published documents by top 10 most productive sources during the time period of 2010 to 2019. The scientific journal of IEEE Access has marked an increasing occurrence in the number of publications in Time-Series Classification using Deep Learning. New researchers using Deep Learning methods on Time-Series Classification tasks are more likely to publish their papers in the IEEE Access journal as it has published around 13 related papers in 2019. Other than IEEE Access, the occurrences of some more sources like Lecture Notes in Computer Science and Remote Sensing journal have developed rapidly since 2018, reaching to over eight annual publications in 2019. Although sources such as Procedia Computer Science journal and SPIE Conference Proceedings started publishing papers related to Time-Series Classification using Deep Learning in early 2015, nowadays they are publishing fewer articles compared to others.
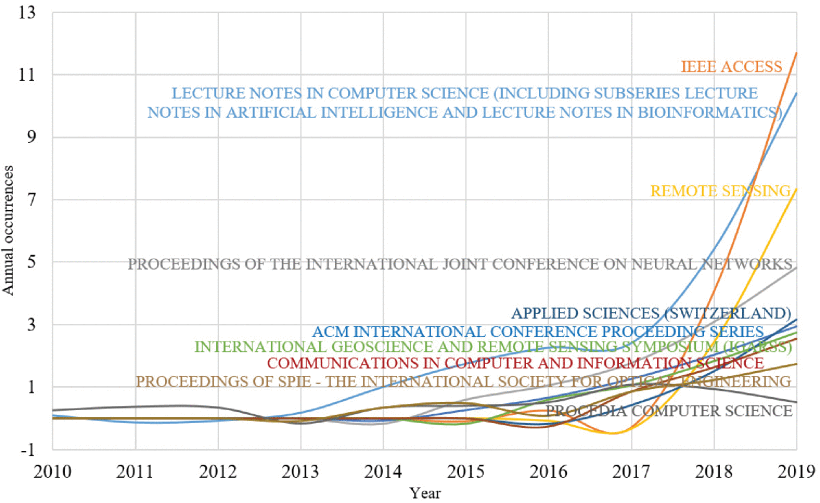
Annual occurrences (with Loess Smoothing) of top 10 sources in time-series classification using deep learning from 2010 to 2019.
Table 2 represents the occurrence of the top author’s keywords in the time span of 2010-2019. The list covers keywords which have appeared at least eight times in all publications included in the analysed dataset. Accordingly, among 982 identified author’s keywords in Time-Series Classification using Deep Learning, only 18 have met the threshold. Deep Learning as the strongest keyword with the total of 81 occurrences, is the most preferred phrase to express the concept. The keywords such as Classification, Time Series Classification, and Convolutional Neural Network/s (CNN) are commonly used in the keywords set of related publications. As Table 2 indicates, researchers are more frequently using CNN methods for classifying time-series datasets compared to Long Short Term Memory (LSTM) or other Recurrent Neural Network/s (RNN) algorithms. Interestingly, all these top author’s keywords have increasing occurrences in recent publications.
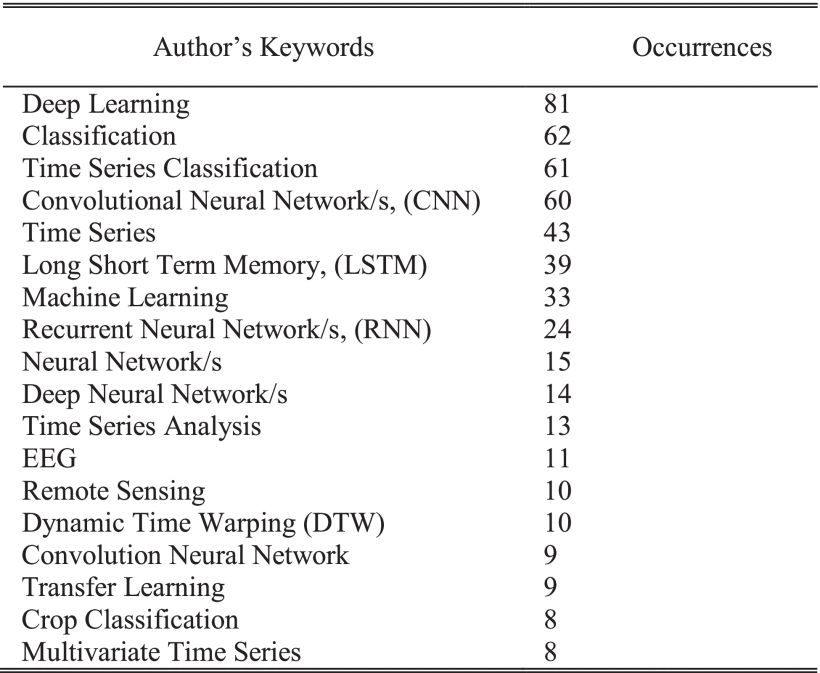
FIGURE 9 visually discovers the extracted keywords index from Scopus database by clustering them into variant categories using clustering techniques in combination with multidimensional scaling (MDS). The conceptual structure map of top 30 index keywords indicates that publications related to Time-Series Classification using Deep Learning can be organised into three main clusters. The red cluster, as the most comprehensive cluster, brings together the index keywords of all publications included in the analysed dataset considering different deep learning algorithms for time-series classification. The cluster contains 19 top index keywords like Deep Learning, Deep Neural Networks, Convolutional Neural Network, Recurrent Neural Networks, Long Short Term Memory, Feature Extraction, Multivariate Time-Series and others.
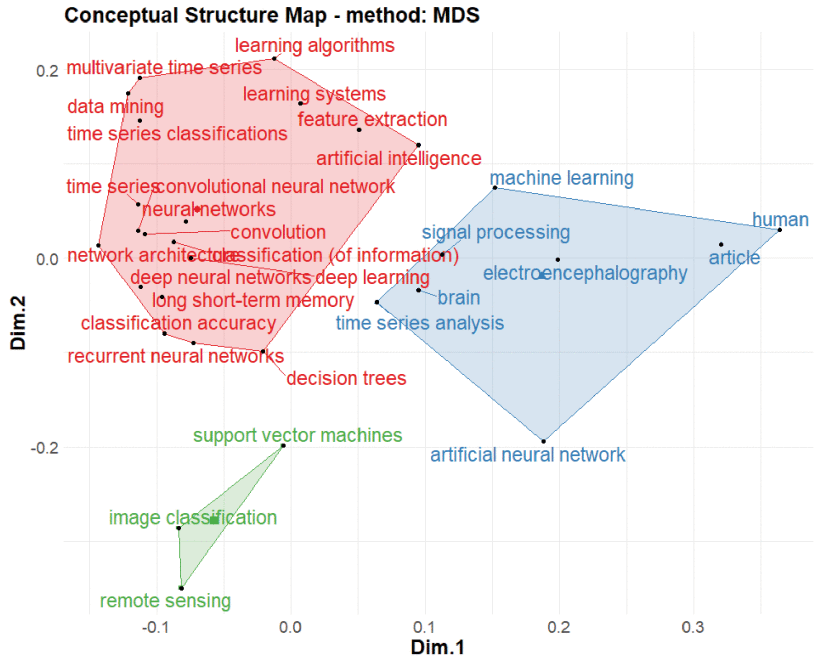
Conceptual structure map (with multidimensional scaling) of top 30 Scopus keywords index in time-series classification using deep learning bibliometric analysis.
The green cluster gathers three index keywords such as Support Vector Machines (SVM), Image Classification and Remote Sensing. Most publications including these index keywords have designed and used deep learning methods for remotely sensed time-series datasets classification. The blue cluster is comprised of the remaining eight top index keywords mainly including Machine Learning, Signal Processing, Human, Brain, Electroencephalography, Time-Series Analysis and Artificial Neural Network. Research articles in this cluster have proposed variant deep learning-based signal classification methods and applications. More specifically, these articles contain general discussions about the usage of previous machine learning or artificial neural network based algorithms.
Qualitative Analysis
Keywords cluster analysis helps identify research trends and status in the field of time-series classification focusing on deep learning methods. The knowledge clusters show prominent groups of themes and characterize the research directions based on the extracted keywords index from the literature. Time-series classification most productive literatures generally concentrate on novel deep learning algorithms and their application in image classification and signal processing. In this section the noticeable research clusters identified through the bibliometric analysis are qualitatively analysed. Keywords index automatic clustering is combined with a qualitative analysis of the publications content.
All documents in time-series classification using deep learning according to Scopus database are sorted by annual citation rate in descending order. Each paper’s citation rate is calculated by dividing total citations received by the number of years passed since publication. Evaluating top-cited papers’ content helps to identify the most significant research topics within the study areas. Publications with the highest citation rate are qualitatively analysed based on all titles and abstracts of the full paper set. The top 50 most frequently cited papers are categorized into common key research directions shown in Table 3 in Appendix. Review papers are excluded from the qualitative analysis set as they carry information about all three categories.

Documents with the highest citation rates are selected from the top of the most-cited articles list for more in-depth analysis. The nominated articles have been cited at least 10 times per year with their average citation rates ranging from 49.00 to 10.40. Top 23 most-cited articles are considered for detailed qualitative analysis since the number of citations per year suddenly drops to 8.20 afterwards. Three main research topics of time-series classification using different Deep Neural Networks (DNNs) algorithms for variant remote sensing and signal processing purposes are conducted during the analysis. The extracted research areas confirm the revealed research clusters of previous factorial analysis. The following section presents an overview of every highly cited paper purpose related to each research cluster.
A. Different Deep Neural Networks Algorithms for Time-Series Classification
Different baseline models are proposed for time-series classification using DNNs. Variant network architectures are capable of providing fully comprehensive baseline models. Plain artificial neural networks baselines such as Multilayer Perceptron (MLP) are considered similar to the best traditional 1 Nearest Neighbor - Dynamic Time Warping (1NN-DTW) baseline. Feature extraction using Fully Conventional Networks (FCNs) has performed better than traditional approaches. Deeper neural networks have also been applied to time-series data using residual networks such as ResNet structure. The different baseline models classify time-series from scratch with minimum complexity [9].
Time-series classification has been done by combining FCNs and LSTM from Recurrent Neural Networks (RNNs) family. LSTM-FCN has supplemented FCNs performance by raising model parameters count and minimizing dataset pre-processing. Although Attention Long Short Term Memory - FCNs (ALSTM-FCN) have provided a strong baseline using attention mechanism, the cells failed in classifying some time-series datasets [57]. Convolutional Neural Network (CNN) framework has improved time-series classification accuracy and noise tolerance by automatically generating deep input features [23]. However, several machine learning algorithms exist, outperforming the standard CNN in terms of time-series classification accuracy [2].
Computer vision classification and imputation algorithms can be used due to time-series encoding as images. Gramian Angular Fields (GAF) and Markov Transition Fields (MTF) are different frameworks used for time-series image translation. A proposed method has combined representations as GAF-MTF images and applied Tiled Convolutional Neural Networks (Tiled CNNs) for classification [58]. Using transfer learning for deep learning baseline models is counted as a replacement for time-series classification from scratch. Transfer Deep Convolutional Neural Networks (DCNNs) has improved the accuracy of different time-series classification by fine tuning the model after pre-training [59].
Different deep learning frameworks are suggested for multivariate time-series (with at least two time-dependant variables) classification. Feature learning using Multi-Channels Deep Convolutional Neural Networks (MC-DCNNs) has improved in performance compared to the traditional feature-based approaches. The baseline represents features at the last network layer as a combination of learned features from univariate time-series of every channel [18], [20]. Multivariate Convolutional Neural Network (MVCNN) is an extension of the CNN framework considering multivariate and lag-feature characteristics for multivariate time-series classification [60]. Both LSTM-FCN and ALSTM-FCN algorithms are recently developed to be used as multivariate time-series classifiers. The method has improved the accuracy and minimized the pre-processing as a result of enhancing the fully convolutional block [61].
B. Applications of Time-Series Classification in Remote Sensing
Deep learning-based classification frameworks have been used as the most efficient approaches for remotely sensed time-series datasets. Time-series observations from multitemporal remote sensing benefits in different vegetation types classification. Different deep learning classification algorithms are applied to process vegetation index (VI) time-series. Landsat Enhanced Vegetation Index (EVI) time-series classify economic summer crops designed by One-Dimensional Convolutional Neural Networks (Conv1D) and LSTM. The Conv1D-based model has achieved the highest accuracy as a multi-level feature extraction. The LSTM baseline model has also been efficient in describing temporal patterns at different frequencies [62].
DNN-based approaches have integrated time-series Landsat information from USDA’s Common Land Units (CLUs) for field-level crop-type classification. The baseline model has applied field-level and in-season classification on corn/soybean dominated fields with higher performance and lower costs [63]. Agricultural land-cover mapping is improving due to the speckle noise in radar images compared to optical images. Three-dimensional crops information is available using multitemporal Synthetic Aperture Radar (SAR) Sentinel-1 remote sensing data. Deep RNN-based techniques have been applied to the radar time-series data achieving great performance classification [64].
Different RNN algorithms such as LSTM model has also classified multitemporal spatial data from satellite images time-series (SITS) using alternative feature representations [65]. For a full representation of land-cover classification information for SITS, a deep learning two-branch architecture as a mixture of CNN and RNN algorithms is proposed [66]. Temporal Convolutional Neural Network (TempCNN) method has also been efficient in more accurate classification of SITS by learning temporal and spectral features automatically [67].
C. Applications of Time-Series Classification in Signal Processing
Deep learning has proposed variant signal classification methods using visual inspection of signals. Many sleep disorders have been recognised via sleep stage (every 30 seconds of signal) classification. DNN methods based on linear spatial filtering and temporal convolutions have exploited the multivariate and multimodal time-series of Polysomnography (PSG) signals containing electroencephalography (EEG), electrocardiography (ECG), electrooculography (EOG), and electromyography (EMG). The model classifies real-time sleep stages performing with minimum computational time and cost compared to convolutional networks or decision trees [68]. Heart interbeat RR time-series are composed into Intrinsic Mode Functions (IMFs) for feature evaluation. DNNs are coupled with deep features extracted from RR time-series and EEG signals for classification of sleep stages [69].
Different deep learning methods are developed for nonstationary time-series classification as EEG signals in motor imagery classification. Multilevel convolutional feature extraction methods have been applied to CNNs for EEG decoding [70]. Restricted Boltzmann Machine (RBM) based deep learning scheme has improved the performance of motor imagery classification using an additional network output layer of Frequential Deep Belief Network (FDBN). In FDBN, frequency domain input of EEG signals is generated by either Fast Fourier Transform (FFT) or Wavelet Package Decomposition (WPD) and passes through RBMs for classification [71]. Semi-supervised paradigm of Deep Belief Networks (DBNs) has provided fast classification of multiple time-series EEG waveforms. DBNs method has also resulted powerful anomaly measurement of clinical EEG signals using raw time-series inputs [72].
Different deep learning algorithms are proposed for multivariate time-series classification using multivariate sensor signals from semiconductor manufacturing process. Advanced Fault Detection and Classification (FDC) along with CNN model (FDC-CNN) has outperformed others by locating time-series information which represent process faults [73]. Similar deep learning approach of DCNN has been applied to manufacturing gearbox fault type and fault severity classification. Underlying deep features of time-frequency images have been extracted for classification. Graphical images are encoded from one-dimensional time-series vibration signals through wavelet analysis. The image processing advantage of DCNNs has resulted great classification accuracy in dynamical systems [74].
Conclusion and Future WORK
The study provides a detailed quantitative and qualitative analysis, based on publications in time-series classification retrieved from Scopus database from 2010 to 2019. The bibliometric analysis on time-series classification discovered the most recent subfield of study as deep learning. The dataset is refined by deep learning exploring the development status in terms of publication years, countries, sources, keywords and topics. The annual publications in time-series classification using deep learning research field has increased in the past 10 years, showing the potential to grow rapidly in the future. The analysis of international cooperation helps fresh researchers to spot potential research collaborators. According to countries related publications, China is the most productive country collaborating with over a hundred publications in time-series classification using deep learning during 2010-2019. The USA is also known as the most collaborative country in this bibliographic set, as American corresponding authors have several collaborations with other nations.
Studying the evolution of journals publishing time-series classification using deep learning research, identifies highly-targeted sources for new researchers of the field. As a result of the source growth analysis, IEEE Access appears to be the highly productive platform in which most researchers on time-series classification using deep learning publish their papers. Finding research hotspots is possible by calculating the total appearances of keywords during this 10-year period. The analysis of author’s keywords occurrence shows that scientific productions in time-series classification using deep learning are mainly concerned with convolutional neural networks, long short term memory, machine learning, recurrent neural networks, deep neural networks, time-series analysis, EEG, remote sensing, dynamic time warping, transfer learning, crop classification and multivariate time-series.
Topical analysis within the field of time-series classification using deep learning provides the active core categories in this area. The factorial analysis of keywords index and the qualitative analysis of top-cited publications content demonstrate the same research themes concentrated on deep learning algorithms, remote sensing and signal processing applications. A large number of publications in time-series classification using deep learning are directing their studies to the different baselines of deep neural networks with special emphasis on deep convolutional neural network frameworks.
This paper is intended to explain how the research frontiers in time-series classification using deep learning area have changed over the past decade. The paper is crucial for understanding the usage of deep learning algorithms for time-series classification tasks and following the research directions for further developments in the field. Research on improving deep learning algorithms and extending their applications for time-series classification tasks are still ongoing. It can be predicted that a wide range of researchers will start working on the mentioned hot research topics of time-series classification research field focusing on deep learning methods, leading to a great number of publications.




No comments:
Post a Comment