JSTOR
What it does
The gender browser provides a multiscale view of gender representation across multiple domains of scholarly publishing.How to use it
Click on any field to and zoom in to that field. Click on the bar on the left to move back up to higher levels of structure. You can also use the hoptree at the top to navigate from field to field.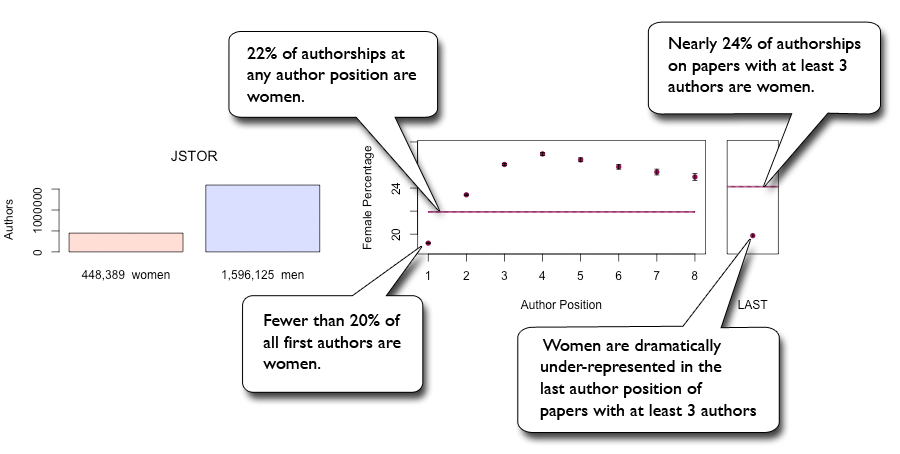
How it works
The JSTOR corpus is a collection of research articles and other documents from scholarly fields including biology, economics, law, sociology, and statistics. (Some areas such as physics and engineering are not well represented in the JSTOR collection and thus are not mapped here.) We use the hierarchical map equation to uncover the structure of disciplines, subdisciplines, specialties, subspecialties, and so forth in the JSTOR corpus, based upon the network of citations among 1.8 million scholarly articles connected by citation and spanning the period from 1665 to 2011. This generates the hierarchical classification of scholarly activities revealed in the gender browser. We have named each field manually by inspecting the papers therein.For each author of each paper in the collection, gender is determined by extracting the given (first) name, and looking at the gender distribution of this name in the US Social Security Administration database; gender is recorded only when we can assign gender with greater than 95 percent confidence.
We have also identified the most influential papers in each discipline and sub-discipline using Eigenfactor algorithms. Click on "top papers" in the top left bar. The data are displayed in the following format: Journal | Year | Title | First Author.
The hierarchical visualization uses the JavaScript InfoVis Toolkit created by Nicolas G. Belmonte.
Personnel
The gender browser was developed under the Eigenfactor Project at the University of Washington in collaboration with JSTOR. The gender browser has been developed by:Questions
For questions, please contact Jevin D. West at jevinw@u.washington.edu
Gender composition of scholarly publications
No comments:
Post a Comment